最近帮朋友做一个数字人项目,要实现上传一段自己的视频,生成一个自己的数字人。
实际上这个项目牵扯到很多技术,包括ASR,TTS,LLM,AIGC等等。前期调研技术就发现有很多实现方案,而且这些方案都在快速更新迭代中。
优云智算注册链接(送40元额度):优云智算
算法调研
目前调研的有几种相关算法,包括声音克隆算法,以及让声音和人像同步的人像生成算法:
声音克隆算法
上传用户自己的一段音频,然后克隆用户自己的音色,相关算法有:
GPT-Sovits
强大的声音克隆及TTS算法。
特点:
零样本语音合成: 输入一个 5 秒的语音样本,即可体验即时的文本到语音转换。
少样本语音合成:仅用 1 分钟的训练数据对模型进行微调,以提高语音相似性和真实感。
跨语言支持:对与训练数据集不同的语言进行推理,目前支持英语、日语、韩语、粤语和中文。
网页界面工具:集成的工具包括语音伴奏分离、自动训练集分割、中文语音识别和文本标注,帮助初学者创建训练数据集和 GPT/SoVITS 模型。
fish-speech
链接:fishaudio/fish-speech: SOTA Open Source TTS
零镜头和少镜头 TTS:输入 10 到 30 秒的人声样本以生成高质量的 TTS 输出。
多语言和跨语言支持:只需将多语言文本复制并粘贴到输入框中 - 无需担心语言。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
无音素依赖:该模型具有很强的泛化能力,TTS 不依赖音素。它可以处理任何语言脚本中的文本。
高度准确:5 分钟英文文本的 CER(字符错误率)和 WER(单词错误率)均较低,约为 2%。
快速:通过加速,Nvidia RTX 4060 笔记本电脑的实时系数约为 1:5,Nvidia RTX 4090 的实时系数约为 1:15。
WebUI 推理:具有易于使用、基于图形的 Web UI,与 Chrome、Firefox、Edge 和其他浏览器兼容。
GUI 推断:提供与 API 服务器无缝协作的 PyQt6 图形界面。支持 Linux、Windows 和 macOS。请参阅 GUI。
部署友好:轻松设置推理服务器,本机支持 Linux、Windows 和 MacOS,最大限度地减少速度损失。
数字人像生成算法
Wav2lip
链接:hyfevian/wav2lip384: wav2lip384生成器网格权重——来自不蠢不蠢
一个很老的唇形同步算法,训练后的wav2lip256/384模型已经商用。
Sonic
sonic是一个先进的音频驱动单图生成动图的算法。
腾讯团队于2025年1月开源的Sonic是一款专注于歌声驱动的数字人项目,其核心功能是通过音频驱动实现精准的唇形同步。该项目具有以下显著特点:
端到端优化
Sonic采用轻量化设计,模型体积仅10G,在保持精度的同时大幅降低硬件要求。使用"甜品级"显卡即可实现10秒视频1分钟的快速渲染效率,这使得实时唇形合成成为可能。多模态驱动能力
除了常规语音驱动外,Sonic创新性地支持歌声驱动场景。通过分析音频频谱特征,系统能同步生成与歌唱韵律匹配的唇部动作,解决了传统技术中乐音与唇形关联性弱的问题。该项目还扩展支持全身数字人动画,突破了仅限面部同步的技术局限。技术架构创新
虽然公开资料未披露具体算法细节,但结合同期技术趋势分析(如中LatentSync的潜在扩散模型、中Wav2Lip的GAN架构),推测Sonic可能融合了以下技术:使用对比学习训练音频-唇形同步判别器(类似SyncNet架构)
采用生成对抗网络实现像素级唇部运动合成
引入时间一致性模块减少帧间闪烁问题
开源生态定位
作为AIGC数字人工具链的重要组成部分,Sonic与DeepSeek、EDTalk等项目形成技术互补。其开源策略降低了数字人制作门槛,特别适合虚拟偶像、智能客服等需要多语言支持的场景(支持中英文等主流语言)。
LatentSync
链接:bytedance/LatentSync: Taming Stable Diffusion for Lip Sync!
LatentSync 是由字节跳动(ByteDance)联合北京交通大学开源的一种端到端唇形同步框架,基于音频条件的潜在扩散模型(latent diffusion models),能够生成高分辨率、动态逼真的唇同步视频。
核心特点
端到端框架
LatentSync 采用端到端的方式,直接从音频生成唇部运动,无需中间的 3D 模型或 2D 特征点,简化了传统方法的复杂流程。潜在扩散模型
基于 Stable Diffusion 的强大生成能力,该框架能够捕捉复杂的音频-视觉关联,生成高质量的唇同步视频。时间一致性增强
为解决扩散模型在不同帧之间扩散过程不一致的问题,LatentSync 引入了时间表示对齐(TREPA)技术。通过大规模自监督视频模型提取时间表示,确保生成视频的时间一致性。多语言支持
LatentSync 支持多种语言的唇形同步,适用于国际内容的配音和本地化。高分辨率视频生成
该框架能够生成高分辨率的视频,同时避免了传统像素空间扩散方法对硬件资源的高要求。
WebUI
前面的算法实际上只是单个的算法,需要将TTS、数字人形象的算法结合,一般有大佬开发了整合包可以用。
LiveTalking框架
LiveTalking 是一个开源的实时互动数字人系统,致力于构建高质量的数字人直播解决方案。该项目采用 Apache 2.0 开源协议,集成了多项前沿技术,包括 ER-NeRF 渲染、实时音视频流处理和唇形同步等。
主要功能
支持多种数字人模型:包括 Ernerf、Musetalk、Wav2lip 和 Ultralight-Digital-Human。
音视频同步对话:实现数字人与用户的实时互动。
支持声音克隆:可以根据输入的声音生成对应的数字人语音。
支持多并发:系统优化了多并发处理,显存不会随并发数增加。
支持 RTMP 和 WebRTC 推流:适用于不同的直播和视频传输需求。
视频编排:在数字人不说话时可以播放自定义视频。
那么要运行这个demo,是需要大量GPU算力及显存的,有一个比较低成本的方案就是租服务器,这里试用过了优云智算,注册送40元额度。
邀请注册链接:https://passport.compshare.cn/register?referral_code=4oHxbgwLwYgDMhBarSx6V8
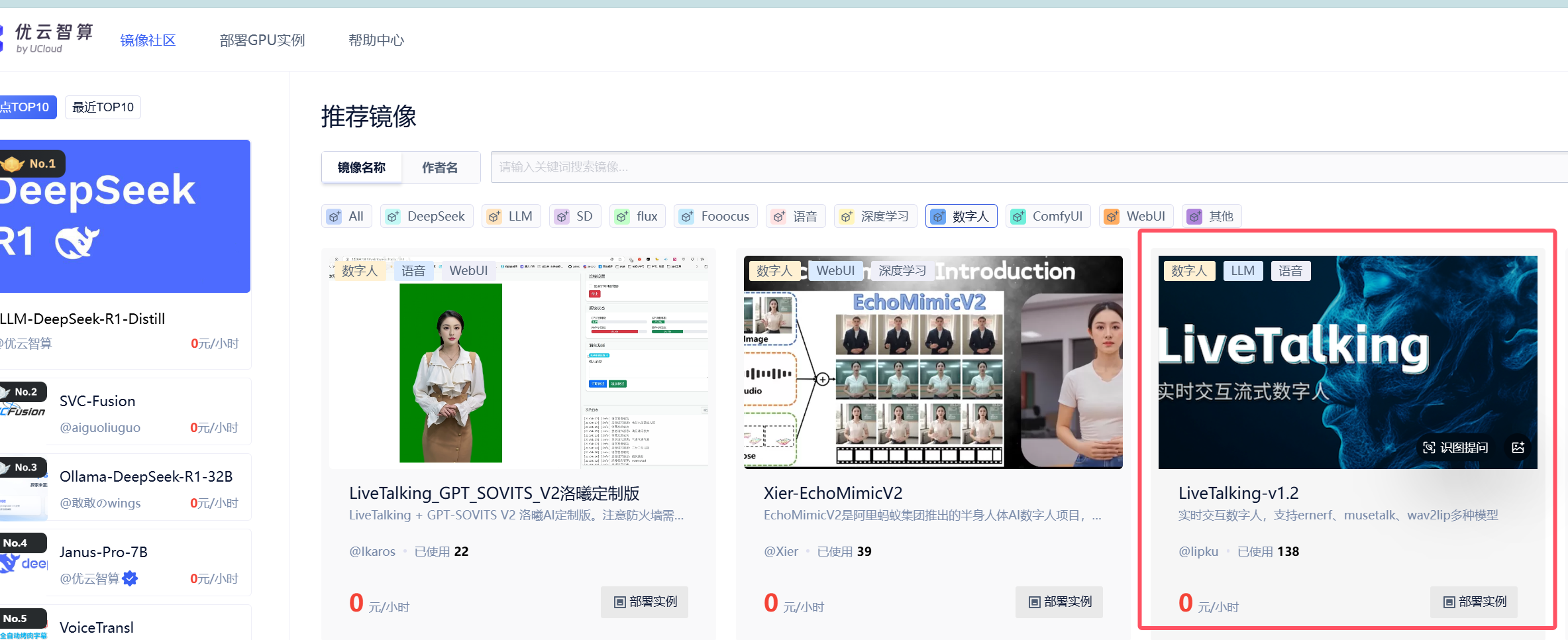
这里有一键部署livetalking的镜像:
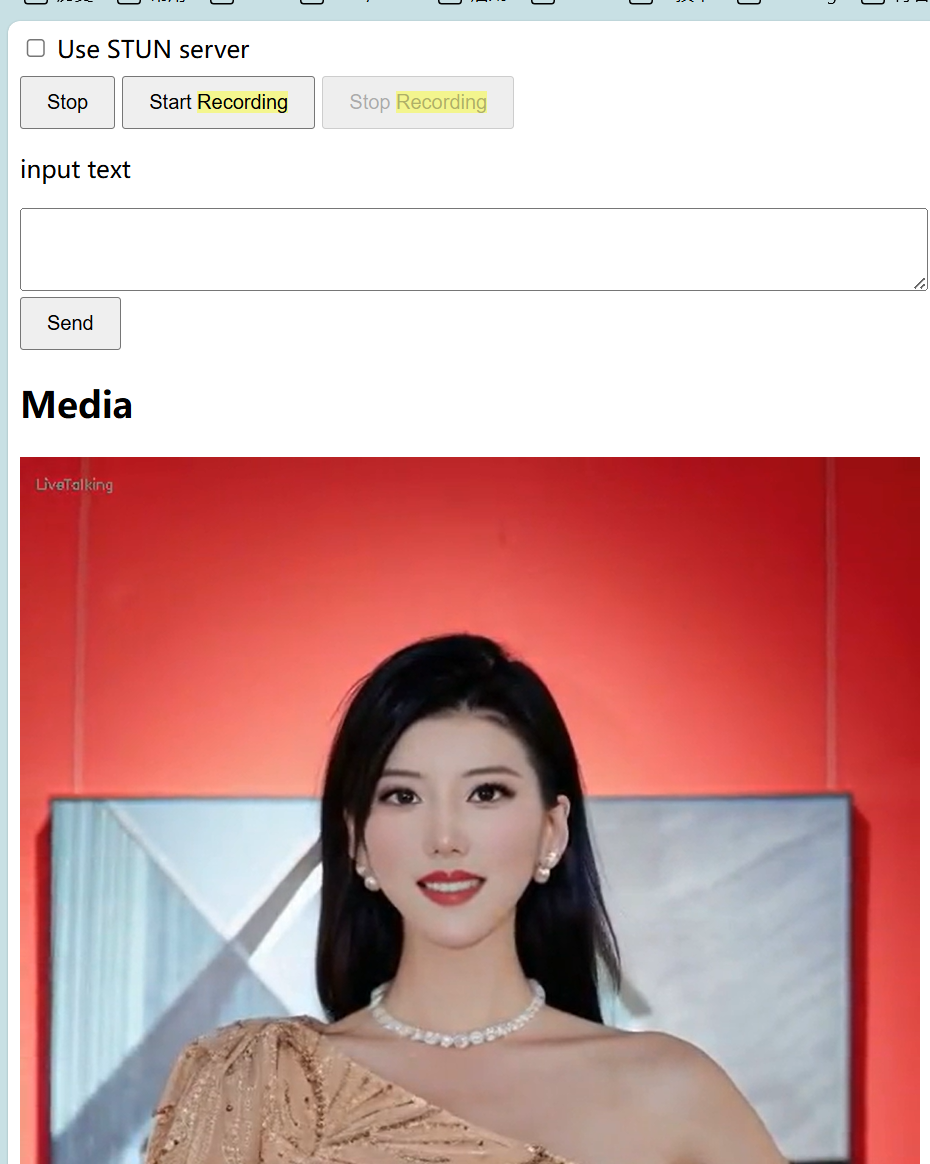
部署成功后启动系统,运行代码:
# 1、启动程序
cd /workspace/GPT-SoVITS
conda activate sovits
python api_v2.py
cd /workspace/LiveTalking
conda activate nerfstream
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts gpt-sovits --TTS_SERVER http://127.0.0.1:9880 --REF_FILE ~/zero_shot_prompt.wav --REF_TEXT 希望你以后能够做的比我还好呦
# 2、最后在浏览器里打开 http://serverip:8010/webrtcapi.html
#点击start,能看到数字人视频。然后输入文字并点击send,数字人会播报文字
#防火墙端口开放tcp 8010,udp 50000-51000
运行结果:点击start,然后输入文本,数字人就会说出输入的文本,还是比较清晰的。